Clustered analysis
Clustered analysis is available in cases where there is a need to compute metrics for entities that are different than the randomization entity.
Common cases include but are not limited to:
- B2B companies that randomize at the company level, but wants to look at user level metrics
- Social media companies that randomize at the user level (for a consistent user experience), but want to look at session-level metrics
Configuring clustered analysis is easy in Eppo. It requires two steps: mapping a new subentity column in the Assignment SQL and choosing clustered analysis as the analysis type when creating an experiment. Metric creation and all other configuration remains the same.
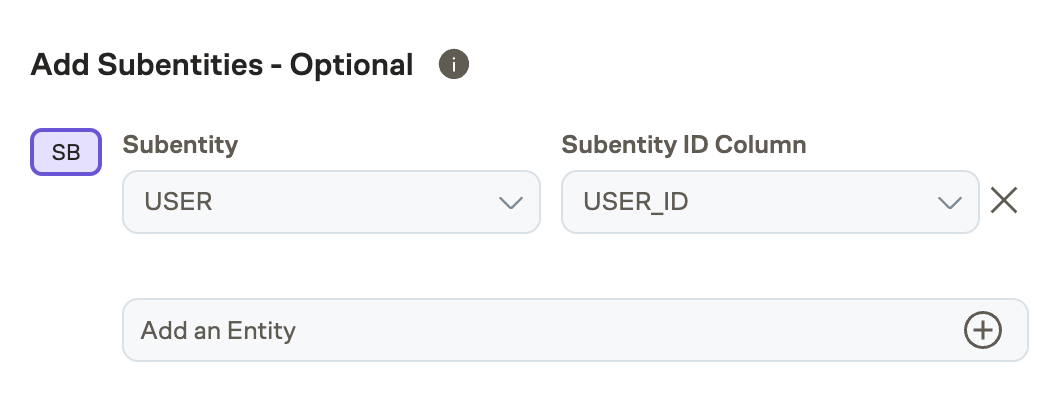
Configuring subentities
Assignment SQL has an optional subentity column. Configure the AssignmentSQL with the main entity and include an additional column with corresponding subentity ids. Select an entity name and select the appropriate column that contains the subentity ids.
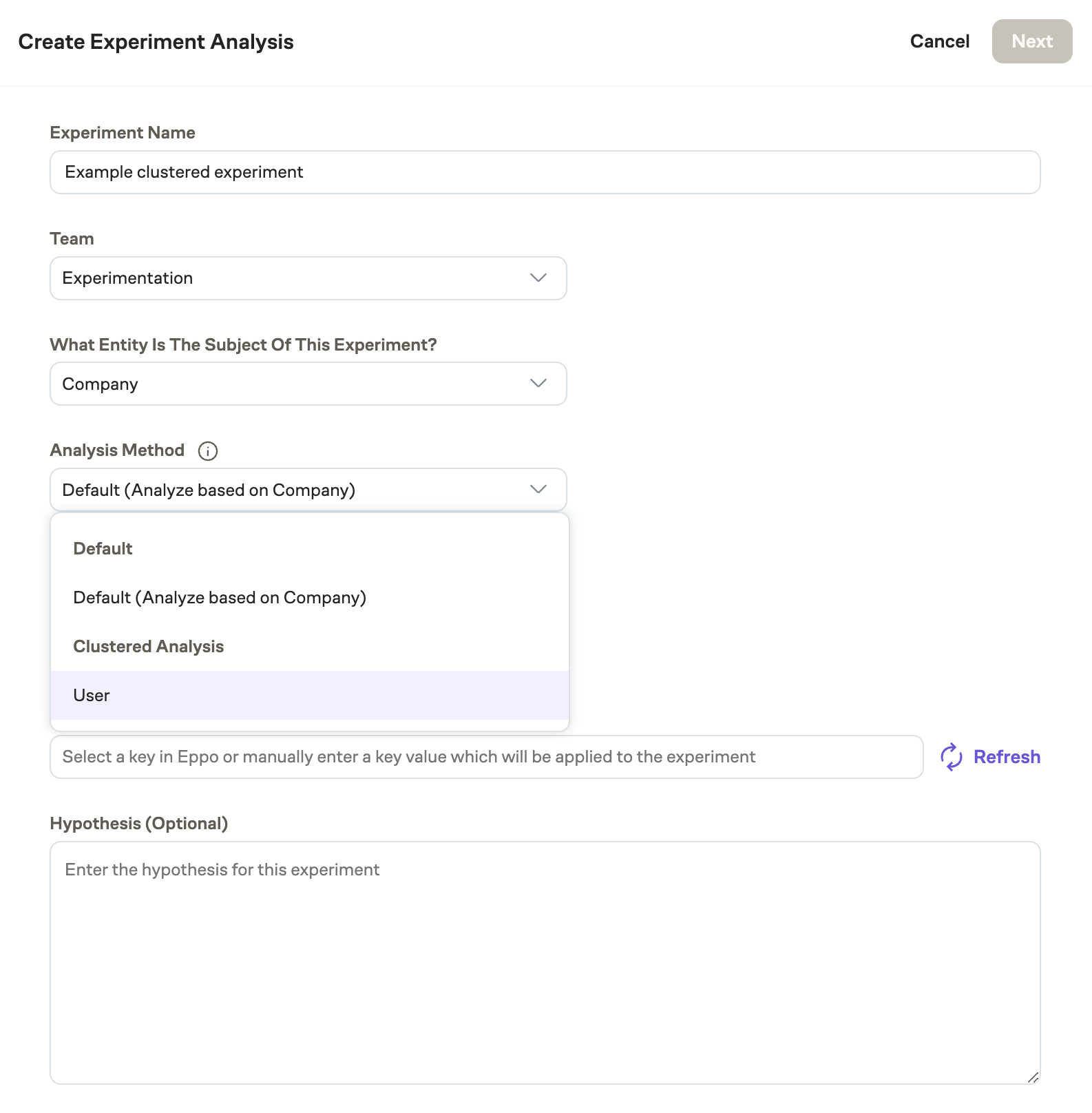
Creating an experiment with clustered analysis
When creating an experiment, choose the randomization entity as usual. Then in Analysis Method there will be a new option for Clustered Analysis with available subentities to choose from.
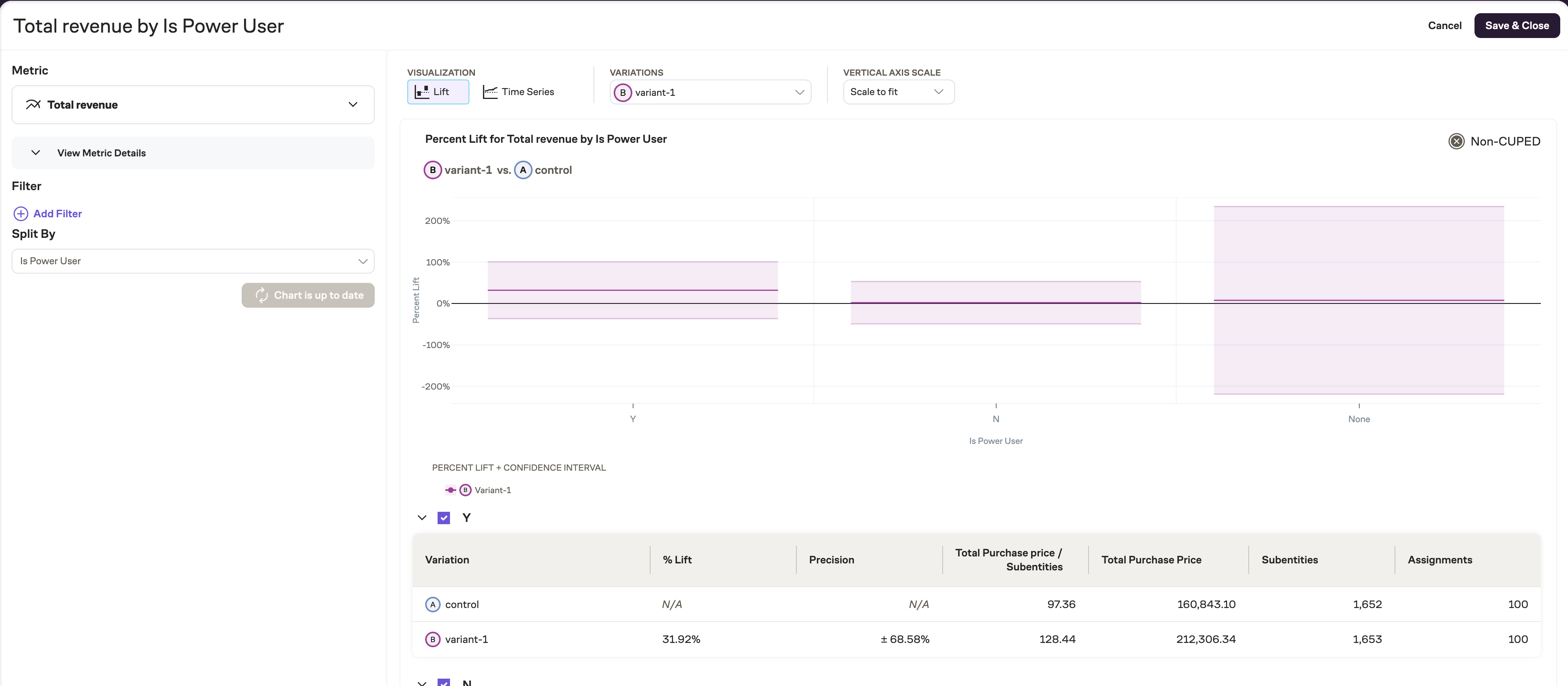
Once created and running, there are a few differences on how experiment results are calculated. Notice that assignment numbers will refer to the entity but subentity numbers will also be available. Metrics will be calculated by using the subentity as the denominator.
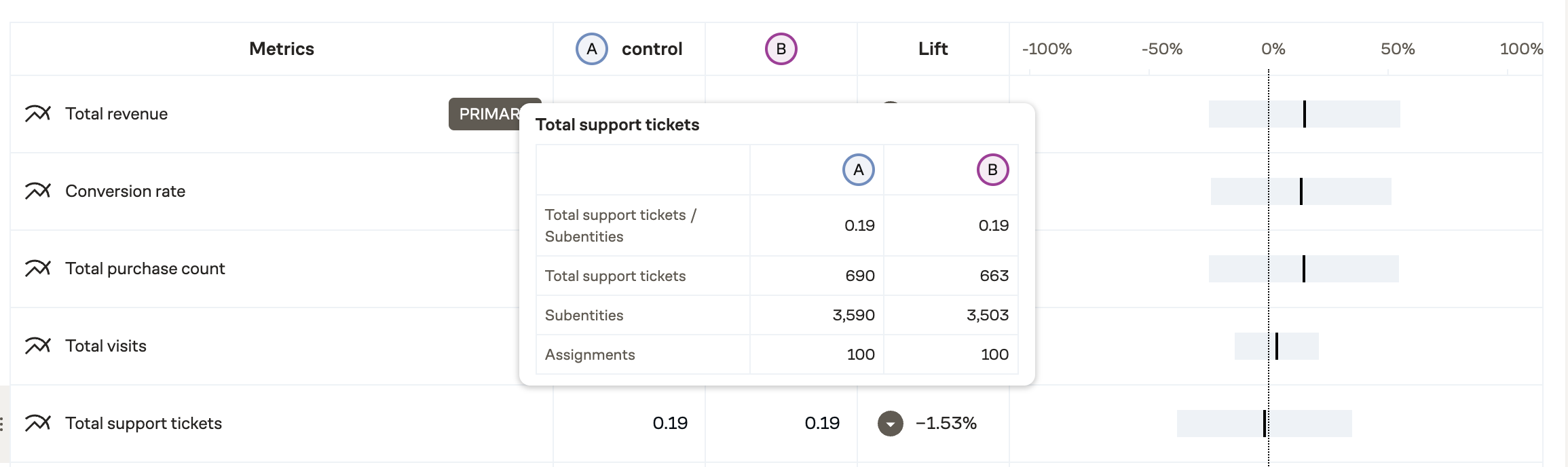
Explore charts behave the same way. Assignment numbers are reported, but metrics and their split bys will use the subentity numbers for the denominator.