Diagnostics
Eppo runs simple checks to ensure your experiment is running smoothly and correctly. All diagnostic checks are scheduled to run with the experiment update schedule, and the results will be automatically refreshed after each run.
Coupled with Slack notifications, Eppo diagnostics alert you to the first sign of an issue with your experiment such that you can fix the issue and minimize lost time to misconfigured experimentation leading to incorrect results.
Each diagnostic contains tools to help you understand, validate, and resolve the issue identified. This information includes graphical representations of the data observed, the SQL we ran that identified the issue, and suggestions on how to resolve the problem. To see more information about a given diagnostic error, click on the “Fix issue” link to the right of the diagnostic.
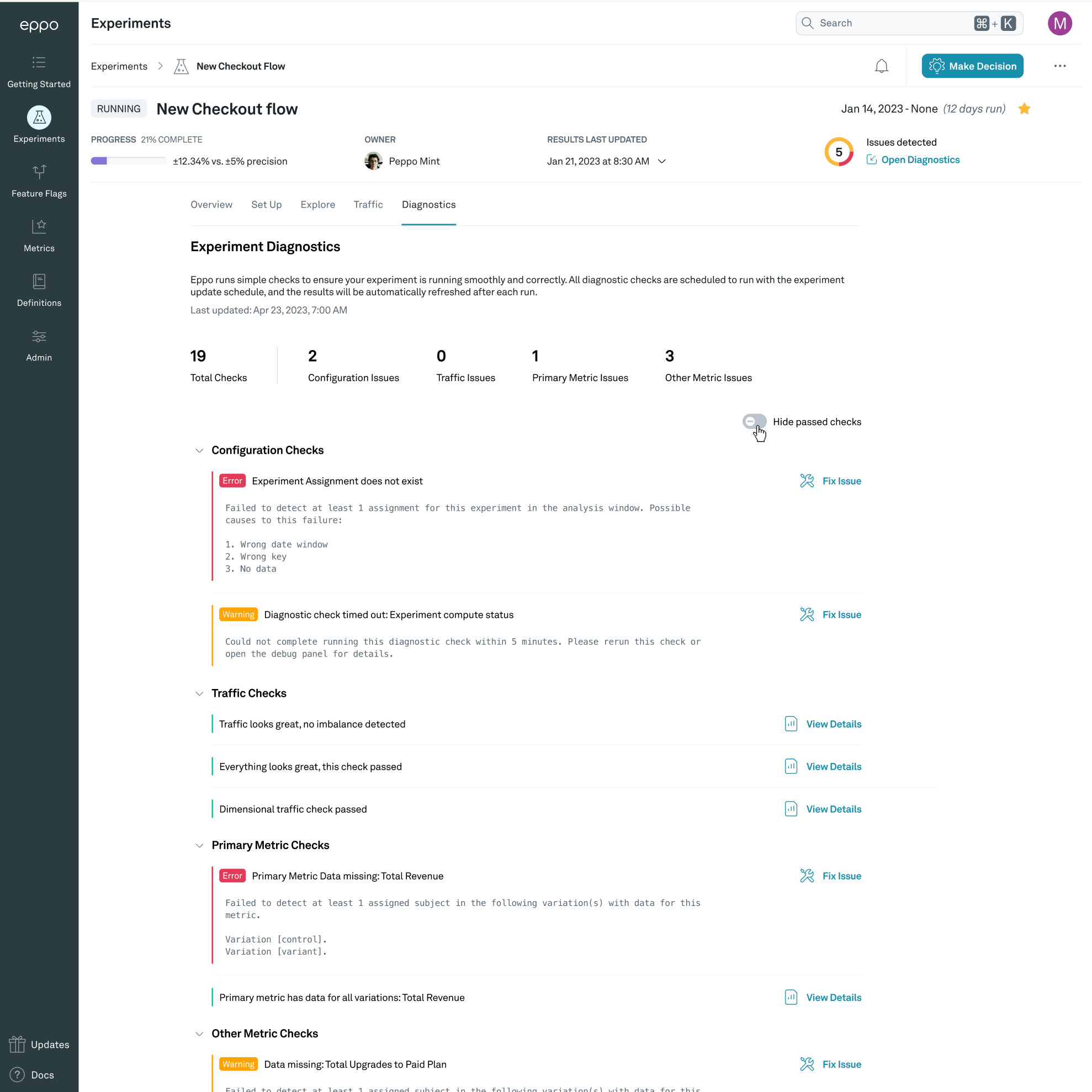
Configuration diagnostics
Configuration diagnostics check that all the underlying data is available for the experiment to run.
Experiment Assignments diagnostic
The experiment assignments diagnostic checks that users are assigned to the experiment within the analysis window. If this check fails probable causes include:
- Incorrect date window
- Wrong experiment key
- No data from the application is making it’s way to the warehouse
Experiment compute status diagnostic
The experiment compute status diagnostic checks that Eppo can reach your warehouse and calculate results for the experiment. If this check fails, please check the error message provided and ensure your data warehouse connection is active.
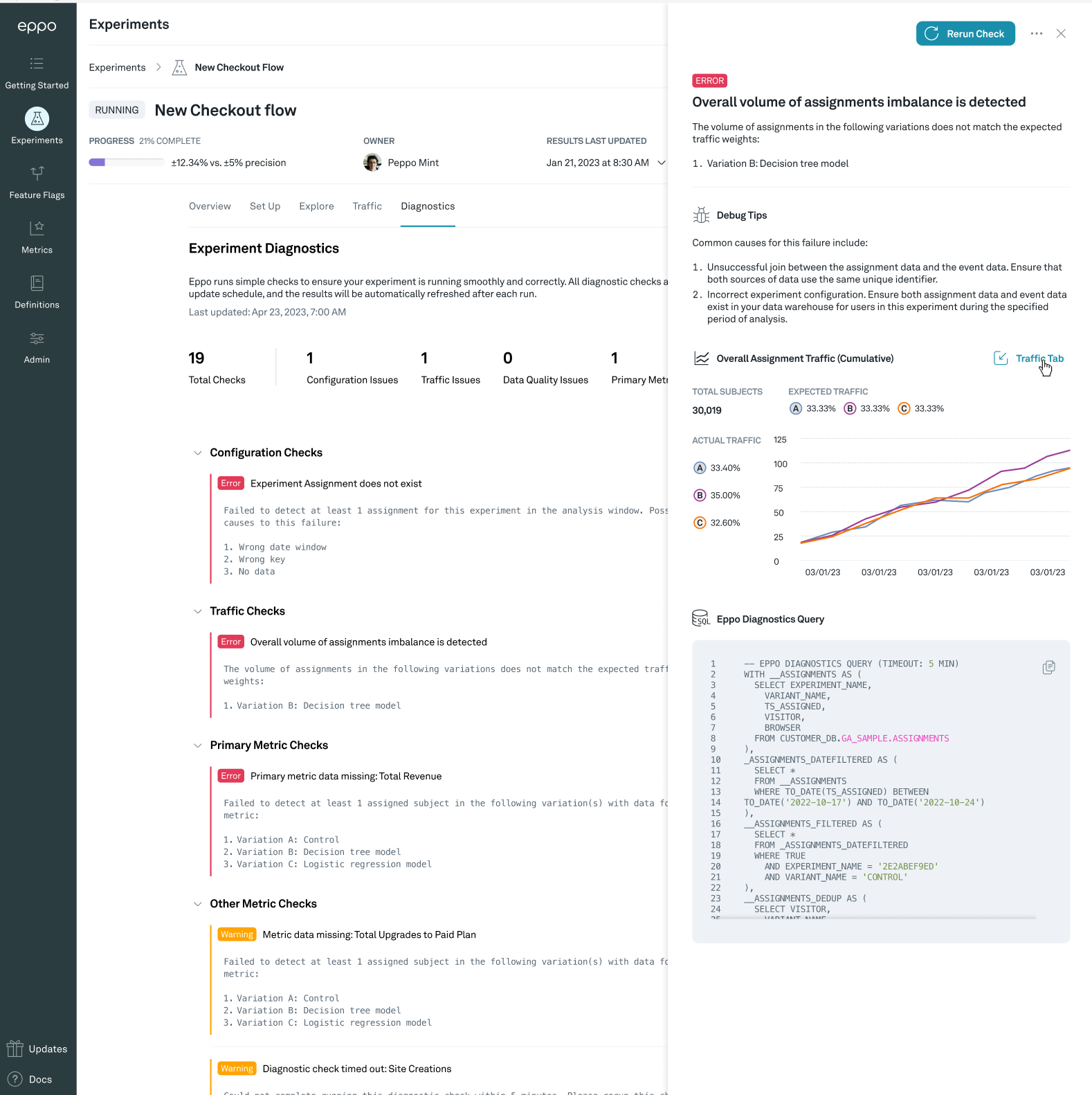
Traffic diagnostics
Validity of experimental results crucially relies on proper randomization of subjects. We use the sample ratio mismatch test to verify that subjects are divided across variants as expected and additionally check that subjects assigned do not jump between variants.
Traffic imbalance diagnostic
The traffic imbalance diagnostic runs a test to see whether the randomization works as expected and the number of subjects assigned to each variation is as expected. This indicates that there is likely an issue with the randomization of subjects (e.g. a bug in the randomization code), which can invalidate the results of an experiment.
We run this traffic imbalance test by running a Pearson’s chi-squared test with on active variations, using the assignment weights for each variant (default is equal split across variations), which we convert to probabilities. This is also known as the sample ratio mismatch test (SRM). We run the test at the more conservative level because this test is not sequentially valid; the more conservative significance level helps us avoid false positives.
Issues with the traffic allocations can come from many sources; here are some common ones we have seen:
- There is an issue with the logging assignments (note this could be introduced through latency)
- Traffic allocations are updated in the middle of an experiments; in general, try to avoid changing the traffic allocations during an experiment
- Assignments for one variant (e.g. the control cell) started before assignments to other variants
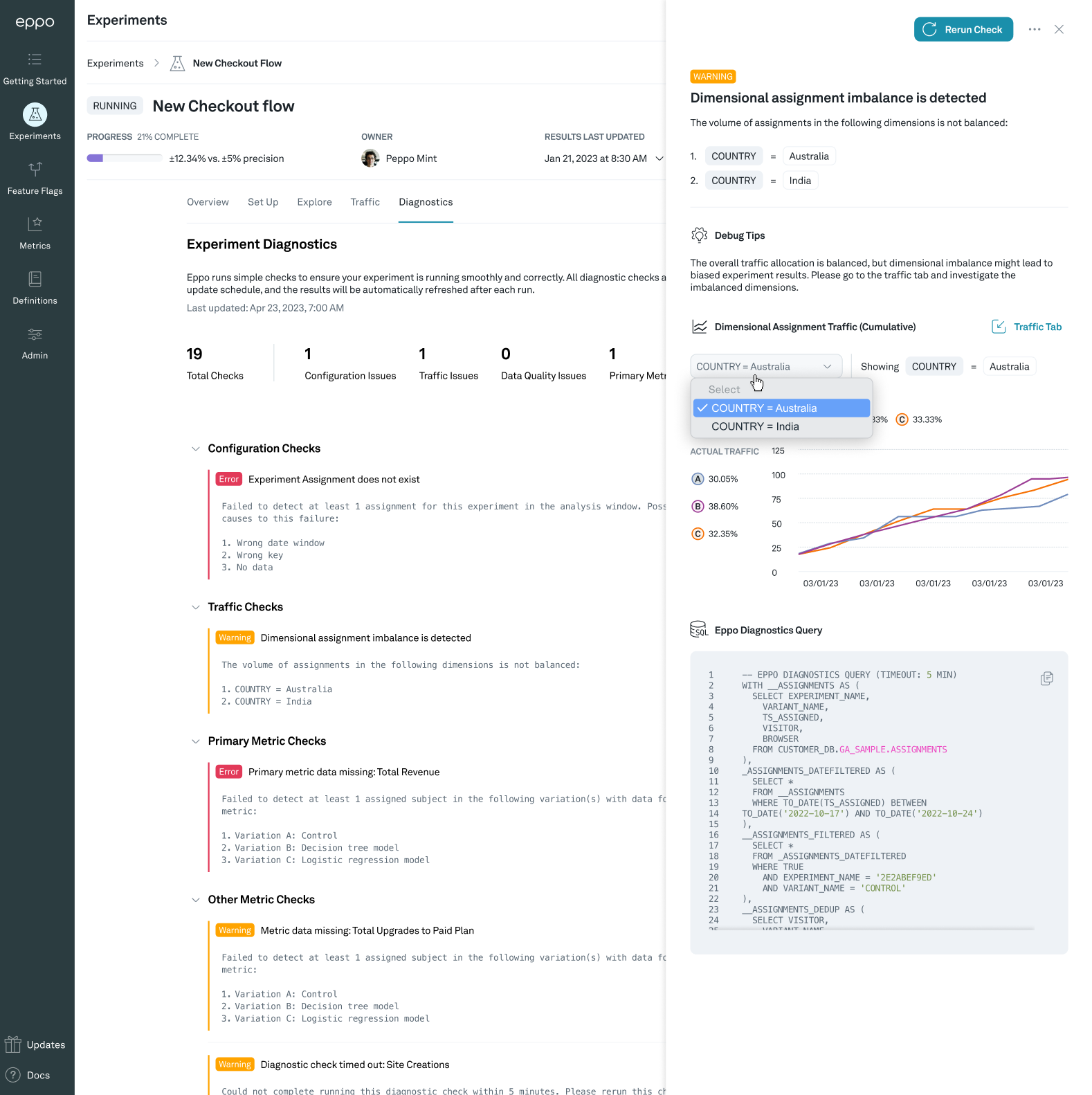
Dimensional imbalance diagnostic
Eppo can also detect when the observed split of traffic across variations within one or more dimensions did not match the expected split. We will highlight the top dimensions where we an imbalance occurring so that you can investigate further.
Mixed assignments diagnostic
Eppo checks if subjects have been exposed to more than one variant and will notify based on the percentage detected. Note that subjects seen in multiple variants will be removed from Eppo analysis.
- Pass - 0-10% mixed assignments detected
- Warn - 10-60% mixed assignments detected
- Fail - 60-100% mixed assignments detected
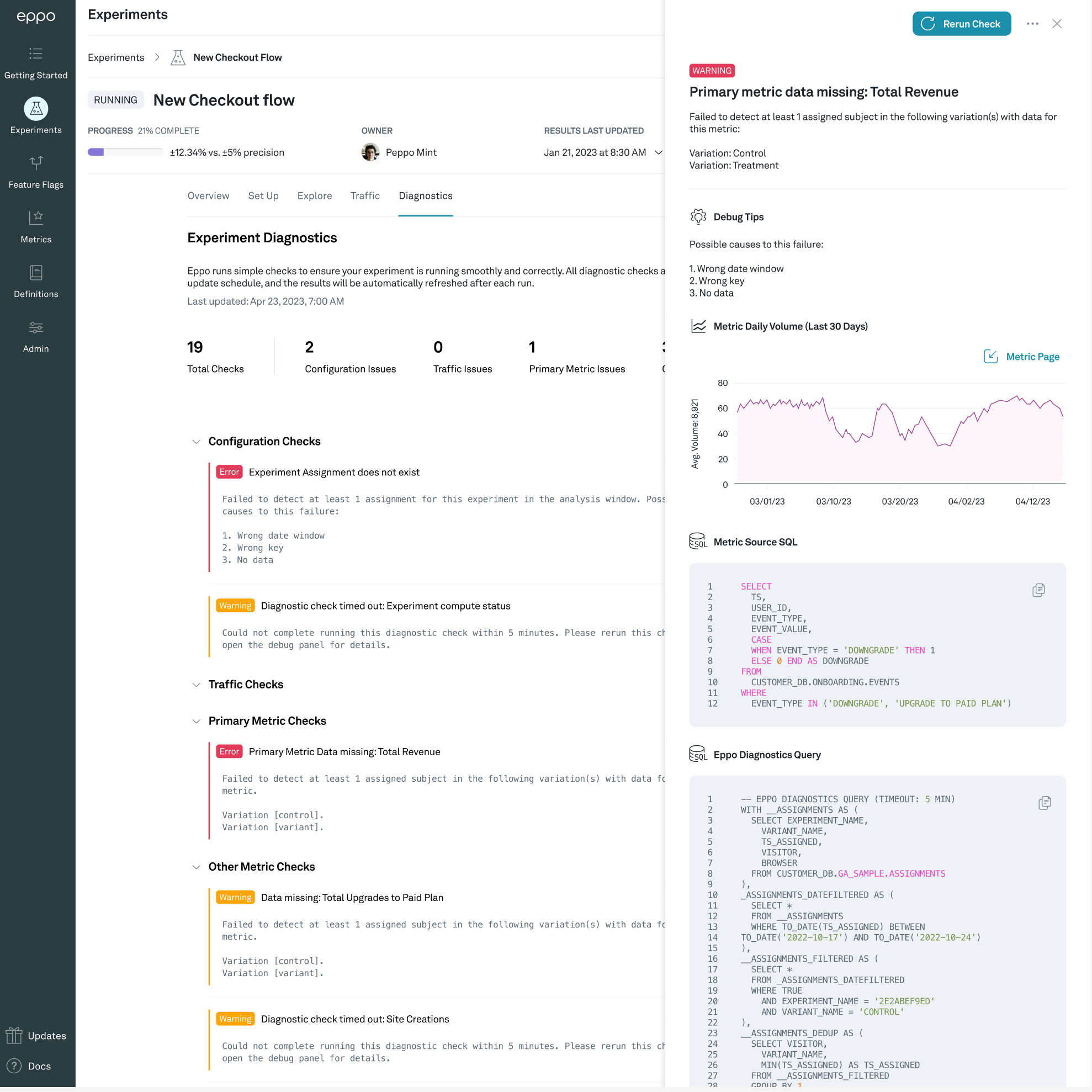
Metric diagnostics
Metric diagnostics check that the metrics being measured in the experiment have data that Eppo can observe. Eppo will run checks against the primary metric in the experiment along with all other metrics being measured.
Common causes for this a metric diagnostic failure include:
- Unsuccessful join between the assignment data and the event data. Ensure that both sources of data use the same unique identifier.
- Incorrect experiment configuration. Ensure both assignment data and event data exist in your data warehouse for users in this experiment during the specified period of analysis.
Data quality diagnostics
Data quality diagnostics check that experiment data matches what we would expect based on pre-experiment data Eppo observes.
Pre-experiment data diagnostic
Eppo detects when pre-experiment metric averages differ significantly across variations for one or more metrics. Eppo will highlight the top metrics where we see this differentiation. This issue is most often driven by the non-random assignment of users into variations within the experiment. Consult with your engineering team to diagnose potential issues with your randomization tool.
The pre-experiment data diagnostic is only run when CUPED is enabled. This setting can be changed in the Admin panel across all experiments, or on a per-experiment basis in the Configure tab under Statistical Analysis Plan.