Deployment modes
Eppo's SDK supports a variety of deployment modes depending on your use case. This page describes a few common patterns for using Eppo, some tradeoffs, and a few anti-patterns to avoid.
How Eppo's SDKs work
Before diving into the different ways to integrate Eppo's SDK, it's important to understand the basics of how Eppo's SDKs assign variants. When you make a change to a flag in the Eppo UI, Eppo will update a configuration object that contains a list of enabled flags, their associated targeting rules, and the variant(s) that each targeting rule is assigned.
The Eppo SDK uses this configuration object to determine what variant a given subject (e.g., user) should see based on that subject's attributes. This configuration is hosted on Eppo's global CDN for high availability around the world.
When initializing the Eppo SDK, you can either tell the SDK to pull this configuration from the CDN or pass in a configuration object you handle manually. In addition, you can specify whether the SDK should load the full rule set configuration, or evaluate assignment logic within an Edge function managed by Eppo.
This may seem like an overwhelming number of options, but it allows Eppo to fully support all of the surface areas that modern development teams might need. In the next section, we'll summarize recommended deployment patterns based on use case.
Summarized guidance
Server-side implementations
For most server applications, we recommend using Eppo's default mode: local flag evaluation using configurations from CDN. This is a simple-to-implement and practical solution that allows you to fetch the latest flag configurations from Eppo's CDN at app initialization and poll for updates at a specified cadence.
Since the configuration contains all of the necessary information to evaluate the flag, the SDK will evaluate the flag locally without any network calls to Eppo. This provides very fast evaluations and decreases network traffic to Eppo's CDN.
Client-side implementations
For the majority of client side applications, the same approach as above is recommended. This leads to simple implementations and doesn't require any subsequent calls to Eppo's network if subject attributes change.
However, there are a few situations where you might want to consider a different approach:
1. Important targeting attributes are not available on the client
If you have subject attributes that you cannot send to your client application, but is available on the server you can use offline initialization from precomputed assignments. In this approach, you'll pre-evaluate all flags on the server side and pass them down to the client as part of routine app initialization. All that is available on the client is a list of flag values (with their names obfuscated).
2. Individual flags have very complex rulesets
In general, the rules file is very lightweight and can be loaded in a few milliseconds. That said, the file gets larger as the complexity of targeting increases. For human-created rules logic, this is typically not a concern. However, if you are using Eppo to run Contextual Bandits with a large amount of context and potential actions, this file can get large.
To prevent loading this whole file to your application, you can instead evaluate the flag in an Edge function managed by Eppo. On SDK initialization, you'll include the relevant context and Eppo will determine which action to take remotely without ever sending the full rule-set to the client. We refer to this pattern as precomputed assignment from Edge functions.
Serverless architectures
Finally, if you are using a serverless architecture, we recommend using a local evaluation from pre-fetched configurations pattern. In this pattern, you'll manage a cache of flag configurations and pass the configurations as an argument when the SDK is initialized in the serverless function. By doing this, you avoid requesting the configuration from Eppo's CDN separately for every call to your function.
Deployment pattern details
In this section we'll dive into the details of each of the deployment patterns mentioned above.
Local flag evaluation using configurations from CDN (most common)
The simplest approach to using Eppo's SDK is to load feature flag configurations from Eppo's CDN during SDK initialization at app start (with optional subsequent polling for updates). Thanks to Eppo's global distribution, this network call typically returns in a few milliseconds. You can see our public latency benchmark here.
Eppo's SDK will then locally determine which variant a user should see based on this configuration. The logging callback function is invoked at the exact moment the user was exposed to the variant. This is ideal from an analysis perspective as only users exposed to the variant will be included in the analysis. That is, there is as little dilution as possible.
As an example, consider an ecommerce site that is running experiments on both a checkout page and a payment page. Here is a sequence diagram for this deployment mode:
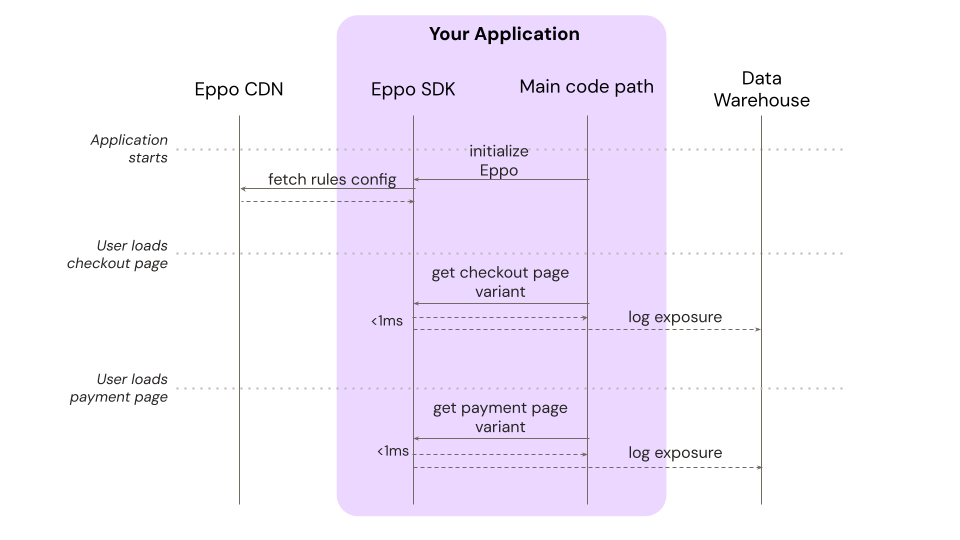
Note that there is only one network call to Eppo, right at the start of the application's lifecycle (optional polling is not shown in the diagram). Eppo's CDN is hosted on Fastly, which provides another degree of redundancy to this deployment pattern: if Eppo had an outage, configurations would remain cached in Fastly and there would be no impact to active feature flags or experiments.
Experiment exposures are logged at the exact moment in time that the user is exposed to the variant. This provides high-quality data to allow experiment measurement to be as precise as possible.
Developer interface
This deployment pattern provides an easy interface for engineers to fetch variants throughout the code base. For instance, in the client-side Javascript SDK:
Initialize once
One time addition when first integrating Eppo's SDK:
import { init } from "@eppo/js-client-sdk";
await init({
apiKey: "<SDK_KEY>",
assignmentLogger: {
logAssignment: (assignmentEvent) => console.log('Send to warehouse: ', assignmentEvent)
}
});
Assign anywhere
Using the SDK to integrate a new flag:
const eppoClient = EppoSdk.getInstance();
const variation = eppoClient.getBooleanAssignment(
'show-new-feature',
userId, {
'country': userCountry,
'device': userDevice,
},
false
);
Offline initialization from precomputed assignments
The approach above works well if you have the full user context available at the time of flag evaluation. If this is not the case, and you instead need to leverage context only available on the server side, you can also precompute flag values as part of your initialization cycle. You can then pass down a list of precomputed flags via an internal API and use that to initialize Eppo's client-side SDK.
Returning to the same ecommerce example, here is a sequence diagram for this deployment mode:
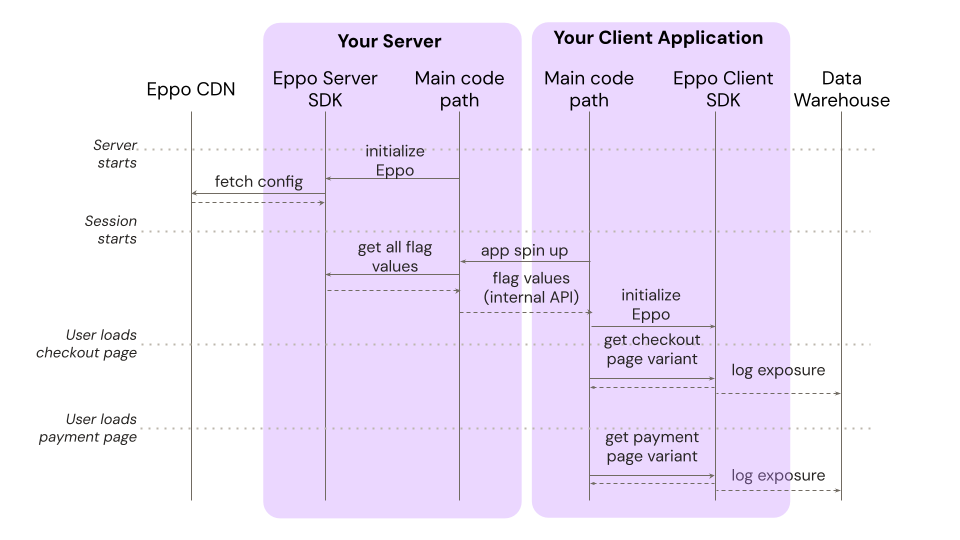
This method allows you to avoid any incremental network calls during app spin up. Since an up-to-date configuration is already stored on your server, Eppo's server SDK can determine a user's flag values entirely locally. Then, when using Eppo's client SDK, there's no need to evaluate rules, much less make a network call to Eppo's CDN.
Exposures are still logged at the exact moment in time that the user sees the variant, providing the same high-quality analytic data as above.
Developer interface
To support this pattern, you'll need to integrate both a server and a client SDK. Once integrated, the development experience to add a new flag is as simple as the previous example. Below is an example using the Node and client-side Javascript SDKs:
Server-side implementation
On server spin up, initialize the Eppo server SDK:
await EppoSdk.init({
apiKey: "<SDK_KEY>",
assignmentLogger: {
logAssignment: (assignmentEvent) => console.log('Send to warehouse: ', assignmentEvent)
},
});
Then, on app initialization, fetch the flag values for the specific user:
const eppoAssignments = await EppoSdk.getInstance().getPrecomputedConfiguration(
'user-123', {
'email': 'dev@example.com'
}
)
// pass the assignments down to the client via internal API
Client-side implementation
Use the assignments computed on the server to initialize the Eppo client SDK:
await EppoSdk.offlinePrecomputedInit({
precomputedConfiguration: eppoAssignments,
assignmentLogger: {
logAssignment: (assignmentEvent) => console.log('Send to warehouse: ', assignmentEvent)
}
});
Everything mentioned above is a one time setup. Now that the SDK is initialized, you can use it as usual for evaluating a new flag:
const eppoClient = EppoSdk.getInstance();
const variation = eppoClient.getBooleanAssignment(
'show-new-feature',
userId, {
'country': userCountry,
'device': userDevice,
},
false
);
Precomputed assignments from Edge functions
If you'd like to avoid the complexity of integrating SDKs on both the client and server side, but still want to minimize latency for complex use cases, you might want to consider having Eppo calculate flag values on the Edge at SDK initialization.
For most use cases, the Eppo configuration file is small and can be loaded in a few milliseconds. That said, there are situations where you may want to optimize the payload size passed back from Eppo's CDN. The most common scenario is when using complex Contextual Bandits logic, which may require a large configuration file including many actions and parameters.
In this case, you can tell Eppo to return a list of pre-evaluated flags instead of the full configuration file. Returning to our example from above, the sequence diagram would look like this:
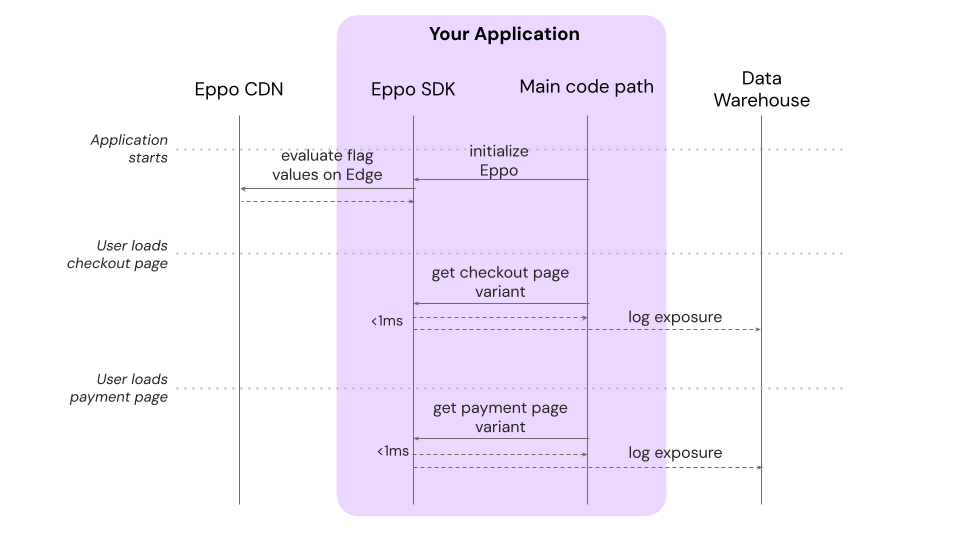
Note that we have many of the same benefits as when fetching the rules file: the integration is simple, evaluation is fast, and we collect high quality exposure data. The only downside to this approach is that you must know the full user context upfront. If this context changes, you'll need to make another request to Eppo's CDN.
Developer interface
The interface for this pattern is similar to when initializing the SDK rules from the CDN. The only difference is that you'll use the precomputedInit and getPrecomputedInstance methods instead of init and getInstance:
Initialize once
One time addition when first integrating Eppo's SDK:
await EppoSdk.precomputedInit({}
apiKey: "<SDK_KEY>",
assignmentLogger,
precompute: {
subjectKey: 'user-123',
subjectAttributes: {
'email': 'dev@example.com'
}
});
Evaluate anywhere
Using the SDK to integrate a new flag:
const eppoClient = EppoSdk.getInstance();
const variation = eppoClient.getBooleanAssignment(
'show-new-feature',
userId, {
'country': userCountry,
'device': userDevice,
},
false
);
Local flag evaluation, initialized with pre-fetched configurations
Finally, you can also initialize the SDK with a pre-fetched configuration object that contains the full rules file. This is useful in a few situations:
- You are using a serverless architecture and want to avoid making a request to Eppo's CDN for every call to your function.
- You want to avoid dependencies on an external network request but don't have full user context available at initialization time.
For this pattern, the sequence diagram would look like this:
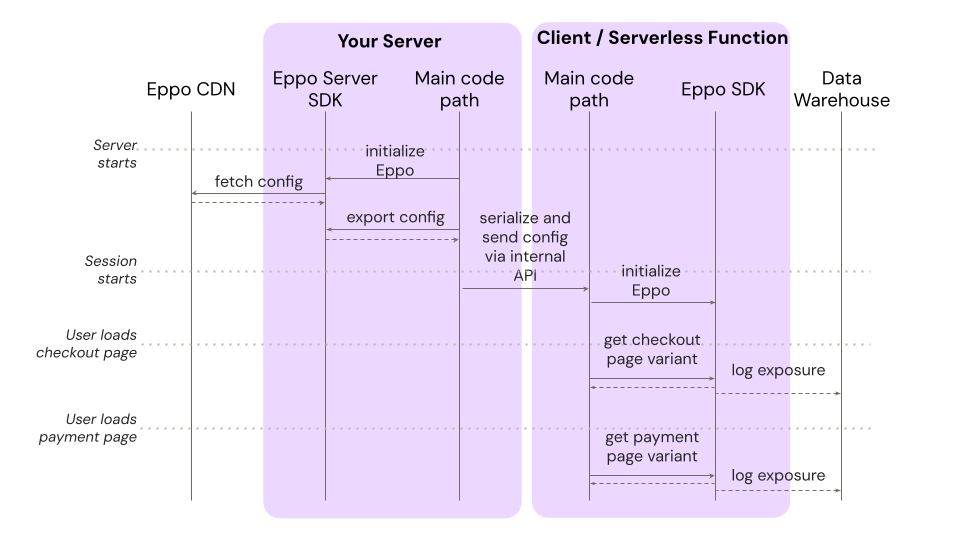
Here your server hosts the rules set and passes it to other surfaces for local initialization. This is similar to the "Offline initialization from precomputed assignments" pattern above, but allows for processing of multiple users as well as realtime updates based on user attributes.
Developer interface
This pattern requires installing the Eppo SDK on both your server and in your serverless function or client application. For example, using the Node and client-side Javascript SDKs:
Server-side implementation
On server spin up, initialize the Eppo server SDK:
await EppoSdk.init({
apiKey: "<SDK_KEY>",
assignmentLogger,
});
Then, fetch flag configurations for downstream initialization:
const flagConfigurations = await EppoSdk.getInstance().getFlagConfigurations();
Initialize SDK from exported flag configurations
When the serverless function is called, or the client initializes, pass the configuration fetched above:
const flagsConfiguration = getCachedConfiguration(); // replace with your caching logic
offlineInit({
flagsConfiguration
});
Assign anywhere
Once this one-time setup is complete, you can use the SDK as usual:
const eppoClient = EppoSdk.getInstance();
const variation = eppoClient.getBooleanAssignment(
'show-new-feature',
userId, {
'country': userCountry,
'device': userDevice,
},
false
);
Patterns to avoid
Initializing the SDK each time a flag is evaluated
A common anti-pattern is to initialize the SDK each time a flag is evaluated. This is unnecessary thanks to Eppo's local evaluation architecture. Further, this causes excessive network calls to Eppo's CDN leading to not just increased latency, but also potential breaching of Eppo's CDN request limits.
Instead, initialize once at the start of the application lifecycle and use the getInstance method when you need to evaluate a flag.
Initializing from CDN in a serverless function
Similarly, make sure to follow the recommendations above for serverless architectures. If you instead make a request to Eppo's CDN each time the serverless function is called, you'll introduce unnecessary latency and risk breaching Eppo's CDN limits.