Welcome to the Eppo Docs
Eppo is a composable next-generation feature flagging and experimentation platform focused on tightly integrating with your existing tech stack.
To get started right away, check out one of our quickstart guides below. Otherwise, read on to learn more about Eppo's approach to experimentation.

Create a Feature Flag
Add a kill switch, plan a gradual rollout, or run an experiment

Create a Metric
Annotate data in your warehouse and create a metric

Analyze an Experiment
Measure the impact of a past or running experiment
Eppo's Architecture
Eppo has two main components: a lightweight SDK to control feature rollouts, kill switches, and advanced experimentation use cases, and an analytics platform for experiment analysis and program management. These two components fit naturally into your tech stack. We have SDKs for most modern development frameworks, and support a variety of deployment options. Our warehouse-native analysis engine is tightly coupled with your existing data, either through our data annotation UI or through our code-based semantic framework.
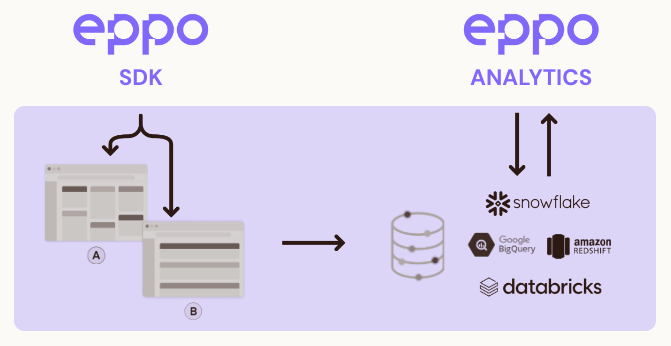
The Eppo SDK
Eppo's SDK supports feature gating, progressive rollouts and randomized experimentation through a simple, reusable interface. Our SDK is designed to be easy to get started with while also providing flexibility for more advanced deployment patterns.
Feature gates and experiments are configured in Eppo's UI. Eppo then turns this into a generalized configuration file and distributes it across our global CDN. On initialization, this file is downloaded and cached locally (either on the user's device or on your server, depending on the SDK). Evaluating which variant a user should see is then done locally within the SDK with no further network requests. Most SDKs will also handle polling for you to ensure the configuration is up to date.

Eppo's SDK does not do any tracking of its own, meaning that no user-level data passes through Eppo's system. Instead you'll pass in a simple interface to your existing event tracking system. In addition to mitigating security risks of using a third party vendor, this also simplifies considerations around ad blocking and cookie consent.
To learn more about Eppo's SDK, see the SDK docs or check out one of our quickstart guides below:
Client SDKs
Server SDKs
The Eppo Analytics Platform
Eppo processes experiment data within your data warehouse environment. This means that no data leaves your system and that you have full visibility into the SQL logic used to produce results. Further, Eppo will always use the latest logic for core business metrics. If this logic or data ever changes, Eppo can automatically recompute results to account for those changes without you having to update any data pipelines specific to experimentation.
Metrics are added to Eppo by pointing Eppo at existing data models in your data warehouse. This can be a basic select * from ... statement, or a more complex SQL definition. Since Eppo's analysis engine is built on SQL, you can be very flexible in defining metrics.
Once you've annotated your data models into Eppo's data model, you can craft metrics using either the in-app metric builder, or in code using Eppo's metric yaml standard.

Eppo is designed so that once a Data team has annotated tables in their warehouse, anyone in the company can use them to plan, monitor, and analyze experiments. This is paired with a comprehensive set of automated diagnostics to ensure that data quality and statistical rigor are both held to a high standard.
Generating an experiment report on Eppo involves five steps:
- Connect Eppo to your data warehouse: Snowflake, Redshift, BigQuery, or Databricks
- Point Eppo at randomization logs from Eppo's SDK, or your own email marketing system, ML models, or other surface area on which you experiment
- Map metric data in your warehouse into Eppo's entity, fact, and dimension data model
- Analyze the impact the experiment had on business metrics
- Perform diagnostics, deep dive on results, and curate learnings in sharable experiment reports
To learn more about Eppo's analytics platform, check out the Data Management and Experiment Analysis sections.
Navigating the docs
The docs are organized into the following sections:
Getting Started
Start here for basic 10 minute tutorials on using core Eppo functionality.
Analysis Integration
SDK Integration
Advanced Use Cases
Core Concepts
- Flag and experiment configuration - Learn the core concepts, workflows, and use cases for Eppo feature flags and how to configure them in the UI, as well as details on advanced concepts like targeting, mutual exclusion, and global holdouts.
- SDKs - Learn about how to install and use Eppo's SDKs into your environment(s), as well as more details on the Eppo architecture and supported deployment patterns.
- Data Management - Learn about Eppo's data and metric model, how to connect your data warehouse, and how to use Eppo to manage data governance across experimentation use cases.
- Experiment Analysis - Learn how to create experiment analysis in Eppo's UI, as well as how to deep dive into experiment results and curate custom experiment reports to communicate and track learnings.
- Contextual Bandits - Learn how to use Eppo to personalize user experiences with contextual bandits.
Reference
- Guides - Dive into detailed guides on advanced use cases including marketing integrations, engineering tutorials, and advanced experimentation topics.
- Statistics - Learn about the nitty-gritty details of how Eppo's statistical engine works, including confidence interval methods, CUPED++, sample size calculation, and more.
- Administration - Learn about Eppo's approach to Role Based Access Control, SSO, SCIM, Teams, and other global admin settings.
Need help? Do not hesitate to reach out to us via support@geteppo.com; we would love to hear from you!