Assignments
Introduction
Assignment SQL Definitions tell Eppo when subjects (e.g., user) are enrolled into experiments, the name of the experiment, and the variant that was assigned. Assignment SQLs either point to logs from Eppo's SDK or another randomization system tracked in your data warehouse. You can create multiple assignment sources if you use a combination of assignment methods.
An example Assignment SQL Definition might looks something like this:
SELECT
ts_assigned,
experiment_name,
variant_name,
user_id,
-- optional properties that may be later used to split results
browser,
device_type
FROM mydb.myschema.assignments
Eppo uses Assignment SQL Definitions to compile a data pipeline that deduplicates assignments, merges them to facts, aggregates these facts into metrics, and performs statistical analysis to measure experiments' impact.
This page walks through Eppo's data model for assignments, including both basic required fields and fields for advanced use cases like clustered experiments and global holdouts. We then provide a walkthrough of creating Assignment SQL Definitions in Eppo's UI and present some examples for both basic and advanced scenarios.
Assignment table schema
This section documents the columns that Eppo expects an Assignment SQL Definition to return. Note that the specific names of these columns do not matter as you will map them into Eppo's data model when you create the assignment definition.
Basic data model
For most use cases, Eppo only requires the following columns:
| Description | Examples | |
|---|---|---|
| Experiment Subject ID | A unique identifier for the subject of an experiment. Used to join to fact SQL definitions. | user_id, anonymous_id, company_id |
| Timestamp | The time at which the subject was assigned. | assigned_at_timestamp |
| Experiment key | A unique identifier for the experiment that this assignment corresponds to. | experiment_id, flag_name, campaign_group |
| Variant | A unique identifier for the experience served. | variant_name, flag_value, campaign_subgroup |
| Assignment property (optional) | Additional categorical information about the experiment subject at time of assignment. Used to measure results by segment, diagnose Sample Ratio Mismatch (SRM), and perform variance reduction with CUPED++. | device_type, app_version, churn_risk_bucket, user_persona |
Optional columns for advanced use cases
Some advanced use cases require additional columns. Examples include performing cross-entity analysis, optimizing data partitioning, and tracking and measuring holdouts. The table below summarized the columns required to support these use cases.
| Description | Examples | |
|---|---|---|
| Secondary ID (optional) | An optional entity ID to use to join on metrics belonging to a different entity than that tracked in the Experiment Subject ID column. Can be a many-to-many relationship, in which case secondary IDs will be attributed to the first observed subject. See the pre-authentication experiments section below for an example. | user_id, email_send_id, search_id |
| Subentity ID (optional) | An optional entity ID to specify a subentity of the primary assignment entity, used for clustered analysis. In this case, the experiment subject can be thought of as a cluster (randomization unit) and the subentity can be thought of as the analysis unit. | user_id, session_id |
| Holdout (optional) | A unique identifier for the holdout of interest. For instance, "2024 Q1 ML holdout". You can read more about holdouts in Eppo here. | holdout_id |
| Holdout variant (optional) | An indicator of whether the user was in the "Status Quo" or "Winning Variants" bucket. | holdout_variant |
| Partition date (optional) | An optional additional timestamp used to filter rows using a column other than the assignment event timestamp. Useful if your assignment timestamp column differs from the table's partition timestamp column. See here for more information about leveraging partitioning. | date |
The advanced features mentioned above are disabled by default. If you would like to enable them, please reach out to your Eppo point of contact or email support@geteppo.com. Enabling these features will have no impact on billing.
Creating an Assignment SQL
We'll now provide a step-by-step walkthrough for creating Assignment SQL Definitions in Eppo's UI.
- Navigate to Definitions, click Create Definition SQL, and select Assignment SQL
- Select the entity (randomized unit) corresponding to unit on which your assignments are randomized: user, anonymous ID, company, etc. To learn more about specifying multiple randomization units in Eppo, see the entities page.
- Name your Assignment SQL
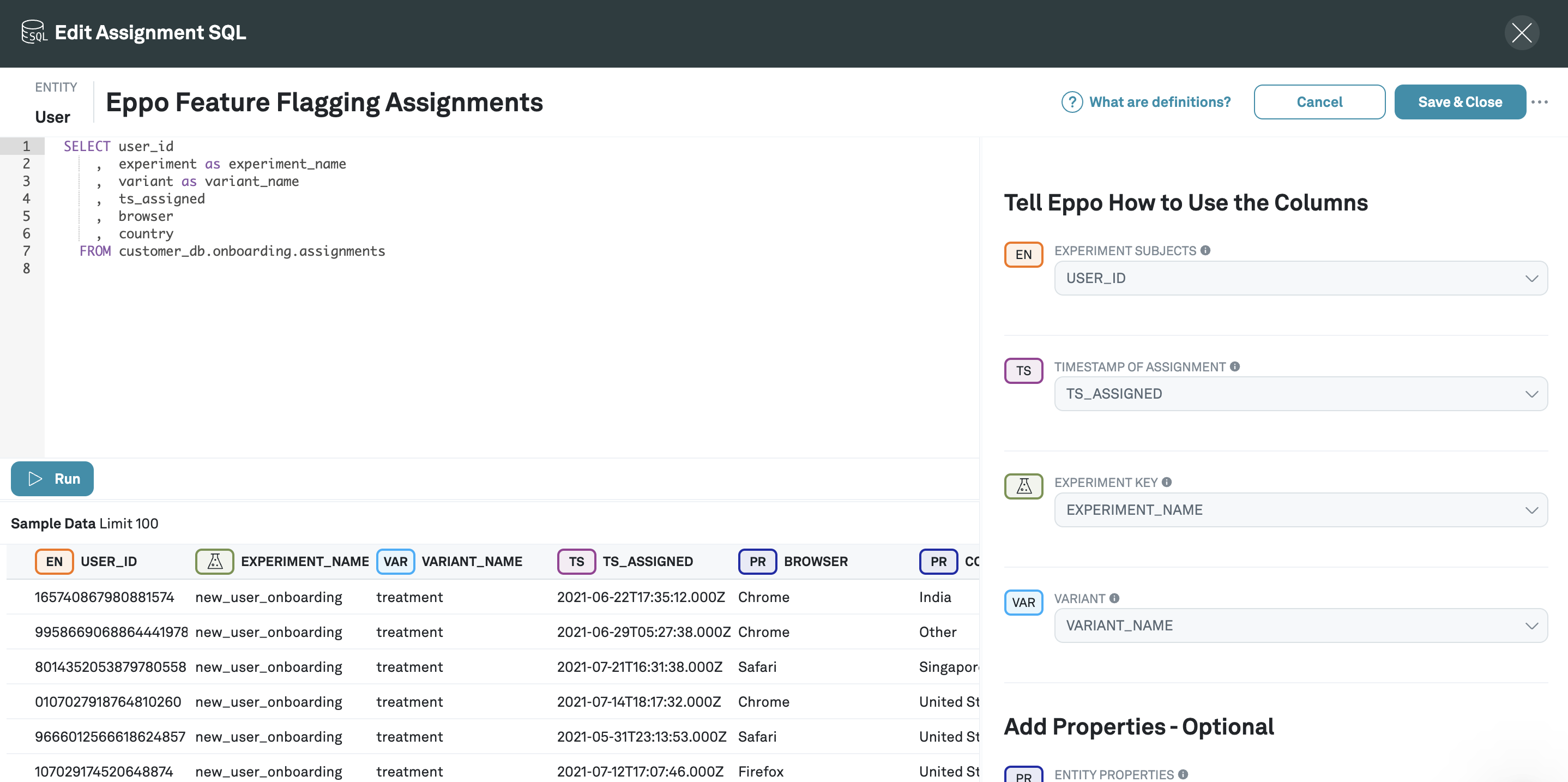
- Write SQL in the SQL editor that returns assignment data from your data warehouse and click Run. At a minimum, this query should return a unique identifier for the subject (e.g.,
user_id), a unique identifier for the experiment, the variant the subject received, and a timestamp. You can also add optional subject properties such as browser or country.
If you do not yet have assignment logs in your warehouse, see the Assignment Logging page.
- After clicking Run, you'll see some sample data. Annotate these columns into Eppo's data model using the right panel:
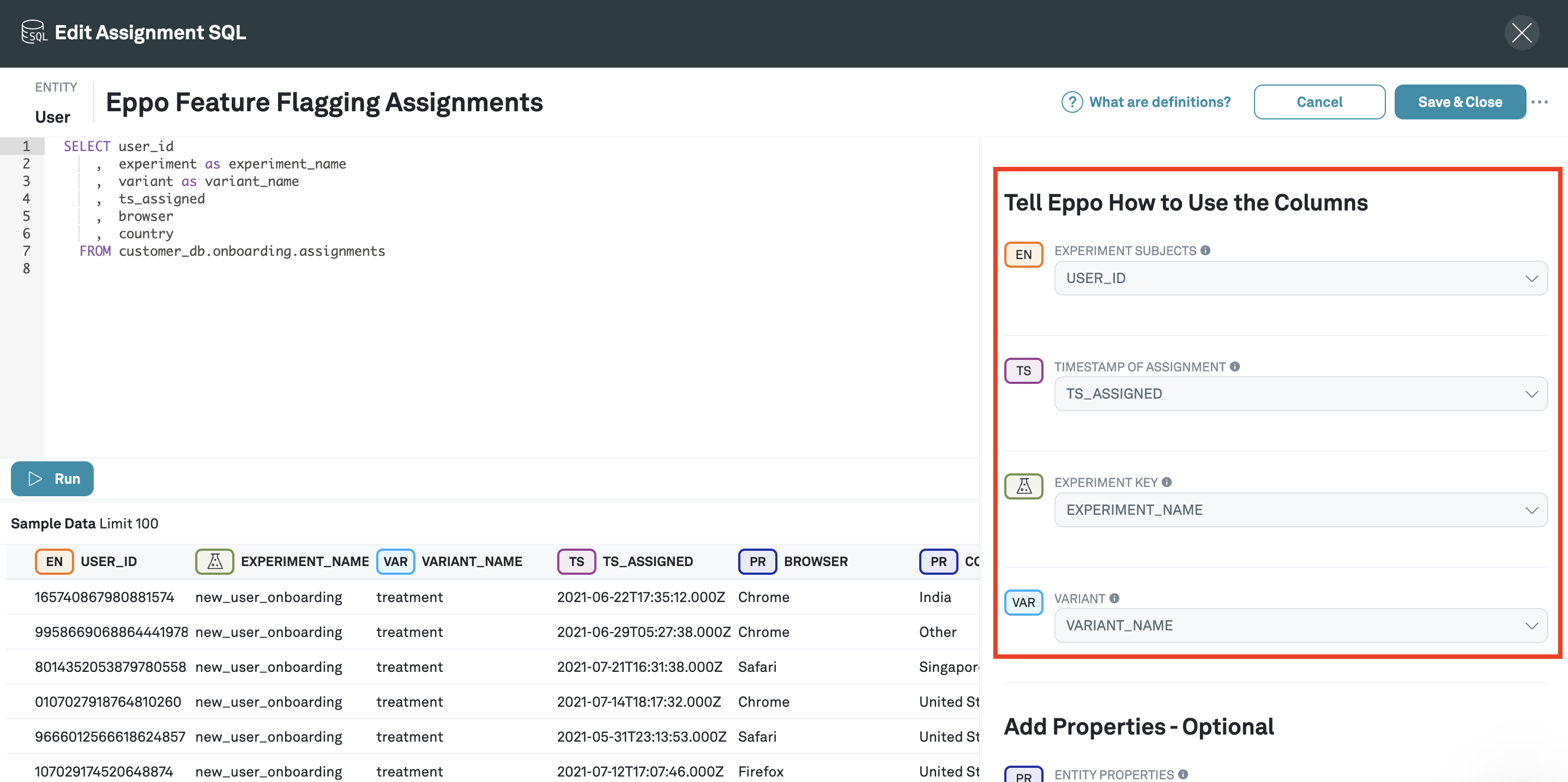
- Once you've finished annotating columns, click Save & Close
Examples
Randomized feature flag logs (most common)
As a simple example, imagine the logs from a feature flagging randomization service. In this case the assignment SQL might return data that looks likes the table below.
| Column | Type in Eppo |
|---|---|
assignment_timestamp | Timestamp |
user_id | Experiment subject ID |
experiment | Experiment key |
variant | Variant |
device_type | Assignment property |
churn_risk_tier | Assignment property |
This example highlights how we can add assignment property from both the assignment event itself (e.g., device_type) along with further analytical models that may only be available in the warehouse (e.g., churn_risk_tier).
When the Eppo analysis pipeline runs, this table will be filtered to records with the a specific experiment value, deduplicated by user, joined to fact SQL definitions, and aggregate data using Eppo' statistical engine.
If SRM is detected, Eppo will check for correlations with device_type and churn_risk_tier, which can help identify the root cause. Further, both device_type and churn_risk_tier will be used as control variables in Eppo's CUPED model, providing increase variance reduction compared to a standard univariate model.
For most companies, the majority of experiments will follow a pattern similar to the one described in this example.
B2B clustered experiments
B2B companies often have the constraint that experiments must be randomized by company, not by user. Nonetheless, you may want to understand the impact on user-level metrics (engagement, etc.) as well as company-level metrics. In this case you can leverage either standard metrics or Eppo's ratio metrics to have average per user.
Alternativly, you can leverage clustered experiment analysis to focus on the individual user affected by the change:
| Column | Type in Eppo |
|---|---|
assignment_timestamp | Timestamp |
company_id | Experiment subject ID |
experiment | Experiment key |
variant | Variant |
user_id | Subentity ID |
Here we've specified company_id as the randomization unit and user_id as the analysis (subentity) unit. Any experiment analysis created using this Assignment SQL Definition can have user-level metrics added to it. Those will analyzed with a method equivalent to clustered standard errors.
For more details, see the page on clustered experiments
Pre-authentication experiments
In many real world use cases, a stable user_id is not available at time of assignment. In this case, a cookie or device ID (generally referred to as anonymous_id) is used to track experiment assignments. You may however want to connect down-funnel metrics that are only tracked with user_id.
Secondary IDs can help here. In addition to adding anonymous_id as the subject key ID, you can add user_id as a secondary ID:
| Column | Type in Eppo |
|---|---|
assignment_timestamp | Timestamp |
anonymous_id | Experiment subject ID |
experiment | Experiment key |
variant | Variant |
user_id | Secondary ID |
Any experiment analysis that uses this Assignment SQL Definition will have both anonymous ID and user-level metrics available. User metrics will be attributed back to the first associated anonymous ID in the assignment table. For more details, see the page on analyzing anonymous user experiments.
Email marketing experiments
When analyzing email marketing experiments, it's common to measure both overall user level metrics (engagement, revenue, retention, etc.) and campaign-specific metrics (click through rate, unsubscribes, etc.). In this case you may want to join only on user_id in some cases, and email_send_id in other cases. This is also supported by secondary IDs:
| Column | Type in Eppo |
|---|---|
assignment_timestamp | Timestamp |
user_id | Experiment subject ID |
experiment | Experiment key |
variant | Variant |
email_send_id | Secondary ID |
Similar to the pre-authentication use case described above, experiment analyses that use this assignment source can measure both user-level metrics and campaign specific metrics.
Assignment deduplication
Eppo will automatically deduplicate assignment logs from the same subject-experiment pair by only considering the first record in the experiment's date range. Eppo will also gracefully handle scenarios where assignment data varies over time for the same subject. Details are described below.
Scenario 1: Subject has assignment events corresponding to more than one variation
In some situations a subject might receive multiple variants within the same experiment. This should be very rare in Eppo-randomized experiments, but may happen in experiments randomized externally from Eppo. In this case, Eppo will automatically filter these subjects out of the experiment results. If the number of subjects filtered exceeds a threshold, a diagnostic alert will appear on the experiment results page.
Scenario 2: Assignment property values change over the course of the experiment
A more common situation is that a subject moves from one segment to another over the course of an experiment. Examples include users that travel from one geographical region to another, or users that move from one user persona to another. When this occurs, Eppo will use the property's value at the time the subject was first assigned to the experiment. This makes results easier to interpret and ensures that there is no data leakage in CUPED.
Updating Assignments
You can update assignments by clicking the Edit button to access the Assignment SQL. At this point you can edit the SQL as you like, but the mapping fields will be locked down until the SQL is validated with a run.
Pressing the Run button will enable the mapping fields. Click Save & Close to save any changes made in either the SQL or mapping.
Any running experiments with assignment based on the updated Assignment SQL will automatically fully refresh on the next experiment update.
Deleting Assignments
You can delete or mark as deprecated an Assignment SQL. First, access the Assignment SQL by clicking the Edit button.
If the assignment is being used, you can click Mark as deprecated; you will see a list of active experiment using that Assignment SQL. New experiments will not be able to use that fact.
To delete an unused Assignments SQL, click Delete Assignment SQL from the overflow menu.
For either action, a confirmation modal will appear detailing the experiments impacted.