Percentile metrics
Percentile or quantile metrics are used to answer two classes of questions. In both of these the usual approach of taking the average value of the metric is not appropriate:
- Performance optimization, such as page load time. Average page load time is typically not a useful metric. First, it is heavily influenced by outliers, such as when the page didn’t load properly or at all and the load time is very high. Second, lowering the average page load time is typically not the goal; making page load even faster for fast loads is not very valuable. The goal instead is to reduce load time for slow loads. Percentile metrics solve both issues, by using p75 (the 75th percentile), p90, or p95 page load time to measure tail behavior.
- Measuring impact on one particular part of the distribution, often the “typical” (median) user. Engagement metrics such as Number of items viewed are often highly skewed. Lifts in the average number of items viewed will be heavily driven by power users who already view many items. Increasing views even further for these atypical users may not be very valuable. The goal instead is to get typical users to view more items. This can be measured by using p50 (aka the median) of the metric. In some cases, the median is desired because it has lower variance than the mean, especially with heavy-tailed metrics.
Creating a percentile metric
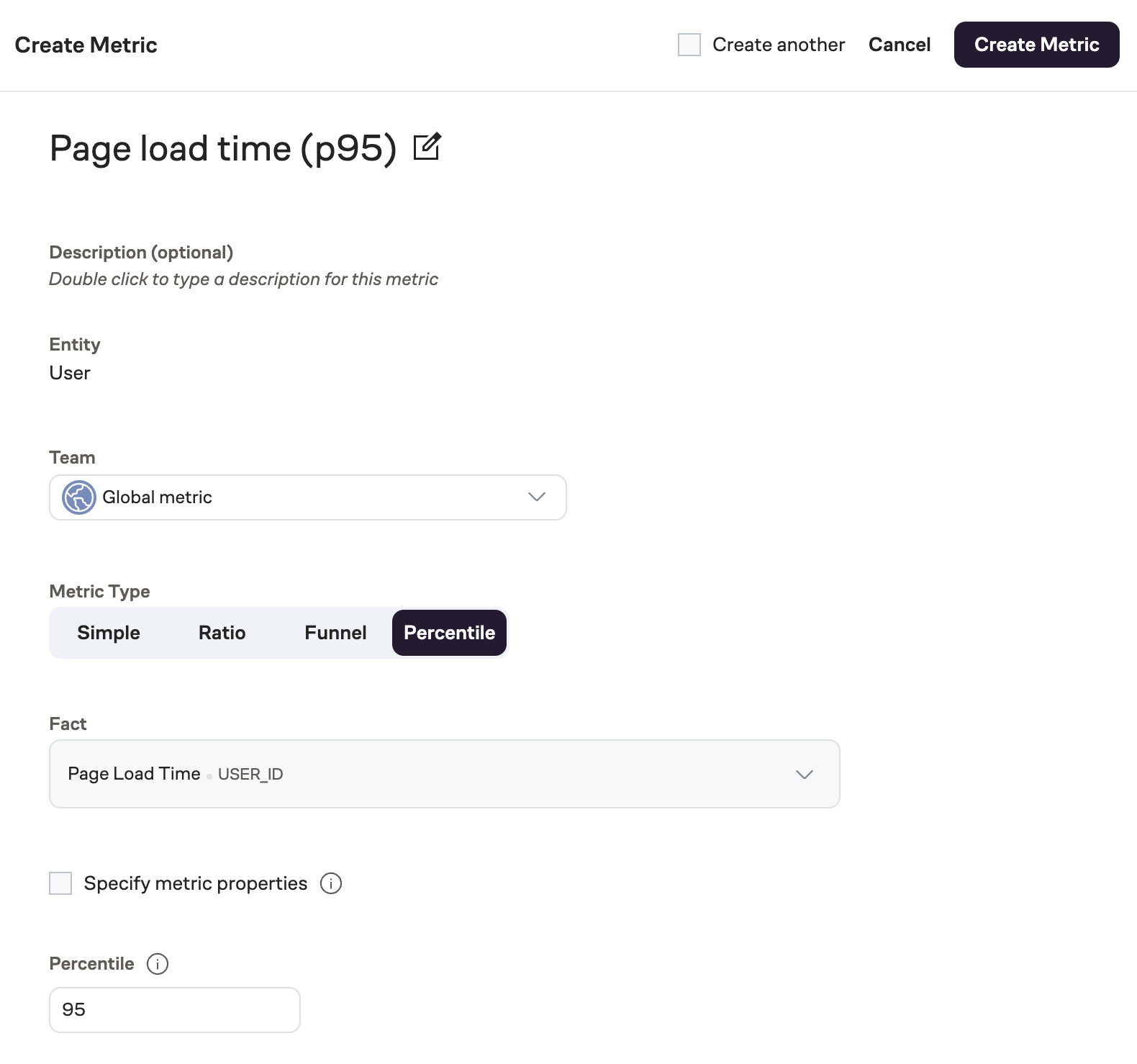
Creating a percentile metric in Eppo consists of the following steps:
- Navigate to the Metrics page, click + Create and select Metric
- Select
Percentileas the metric type - Select the fact you wish to analyze
- Specify the percentile threshold you wish to measure
Percentile calculation and statistics
Percentile metrics are calculated over the raw observations directly. In a page load time example, each fact records one page load time, and for each user many page load times are typically observed. The percentile is defined over all page load observations, pooled across all users. The clustering structure (which page load belongs to which user) does not matter for calculating the point estimate, but is used to get the confidence intervals right.
To create the confidence interval, we use the algorithm that was introduced in Deng, Knoblich, and Yu (2018) (”outer CI with post-adjustment algorithm”, at the end of section 4.2), and restated with somewhat more explicit details as Algorithm 1 in Yao, Li, and Lu (2024).