Analyzing anonymous user experiments
For many experiments it is necessary to assign users to a variant before they have logged in. In this case, there is not yet a User ID to track experiment participants and instead teams must rely on anonymous identifiers such as cookies or device IDs. For these experiments however, it's often desirable to understand the impact on downstream events tracked only at the User ID level. To further add complexity, users may transition between authenticated and unauthenticated states several times over the course of the experiment.
For instance, consider an ecommerce company that maintains a table of events tracking user clicks and their progress through the purchase funnel (e.g., add-to-cart, checkout, and purchase events). Prior to making their first purchase and authenticating, any events generated by a user will not be associated with a User ID. Once the user authenticates, their events can be linked to a User ID as long as they remain logged in. However, if the user logs out, subsequent events will not be associated with a User ID until they authenticate again. This situation can result in time periods where important events are not linked to a User ID.
In a typical single-entity experimentation model, this can lead to a lot of data engineering overhead. Either every pre-authenticated (Anonymous ID) table needs to have a User ID back-populated, or every post-authentication (User ID) table needs to have an Anonymous ID forward propagated. Fortunately, Eppo can simplify this by stitching together events tracked by Anonymous ID with those tracked by User ID.
This page walks through how to set up anonymous user experiments in Eppo using the default attribution logic. We also touch on some practical data engineering and statistical considerations. Finally, since many teams prefer to centralize their attribution logic across use cases, we also discuss a "bring your own" approach to attribution.
Assignment logs with multiple identifiers
Imagine you have an assignment table that looks like this:
| Anon ID | User ID | Timestamp | Experiment | Variant |
|---|---|---|---|---|
| anon1 | NULL | 2024-07-01 00:00:00 | new-checkout | control |
| anon1 | 1 | 2024-07-01 10:00:00 | new-checkout | control |
| anon1 | 2 | 2024-07-01 12:00:00 | new-checkout | control |
| anon1 | NULL | 2024-07-02 12:00:00 | new-checkout | control |
| anon2 | NULL | 2024-07-02 00:00:00 | new-checkout | treatment |
| anon2 | 1 | 2024-07-02 10:00:00 | new-checkout | treatment |
| anon3 | NULL | 2024-07-03 00:00:00 | new-checkout | control |
| anon3 | 2 | 2024-07-03 10:00:00 | new-checkout | control |
| anon4 | NULL | 2024-07-02 10:00:00 | new-checkout | treatment |
This example highlights how in general the relationship between User ID and Anonymous ID is many-to-many. That is, one Anonymous ID can be associated with multiple User IDs (a device is shared across two users) and one User ID might be associated with multiple Anonymous IDs (one user clears their cookies or has two devices).
Eppo can gracefully handle this many-to-many relationship as well as assignment data with missing or duplicate records. When processing the assignment data, Eppo will perform the following clean up steps:
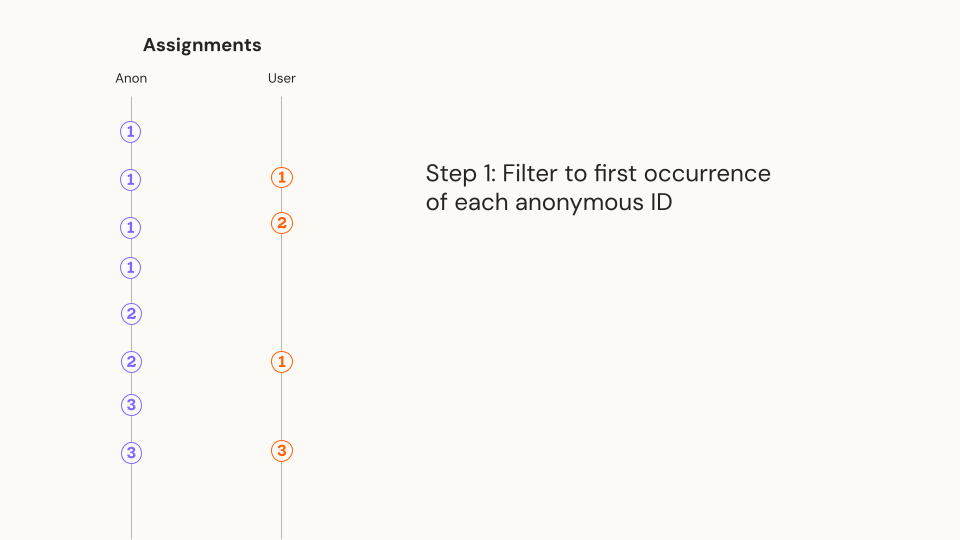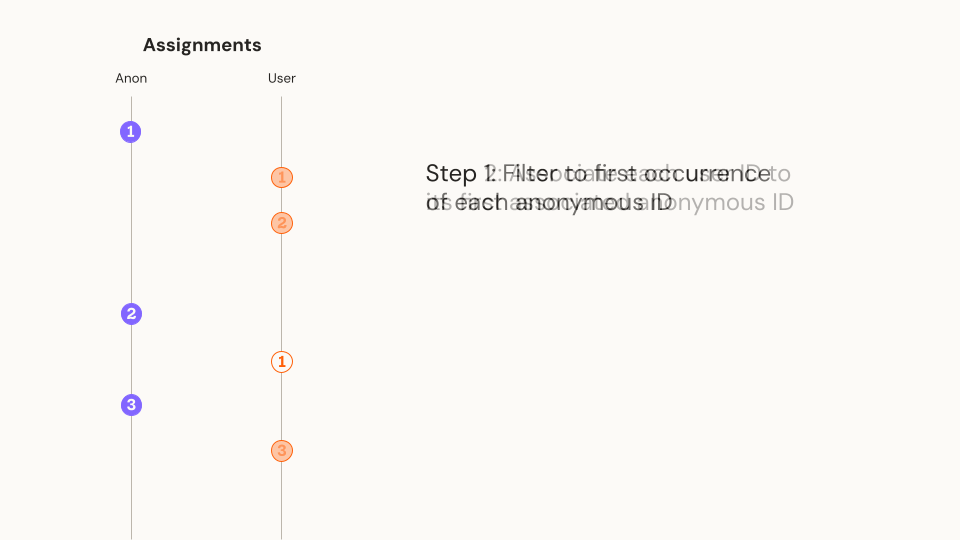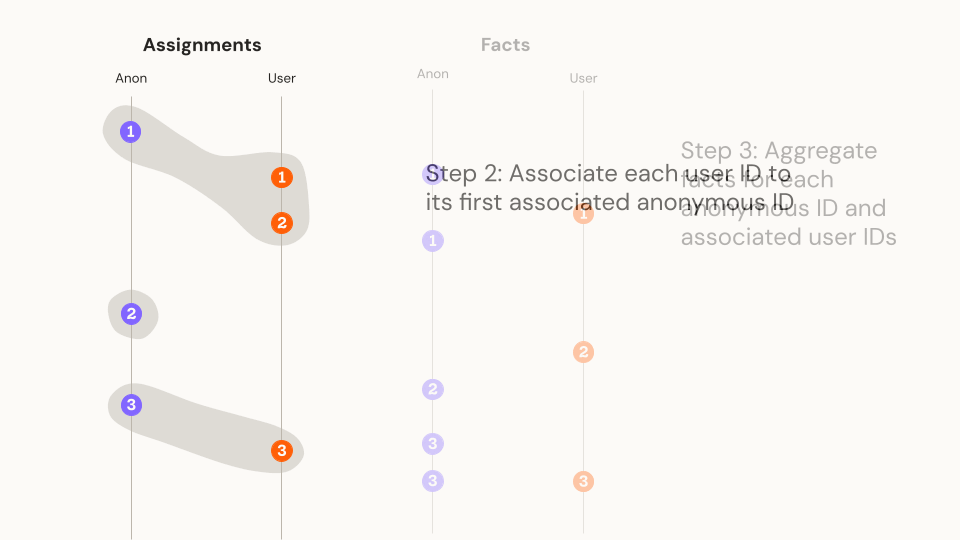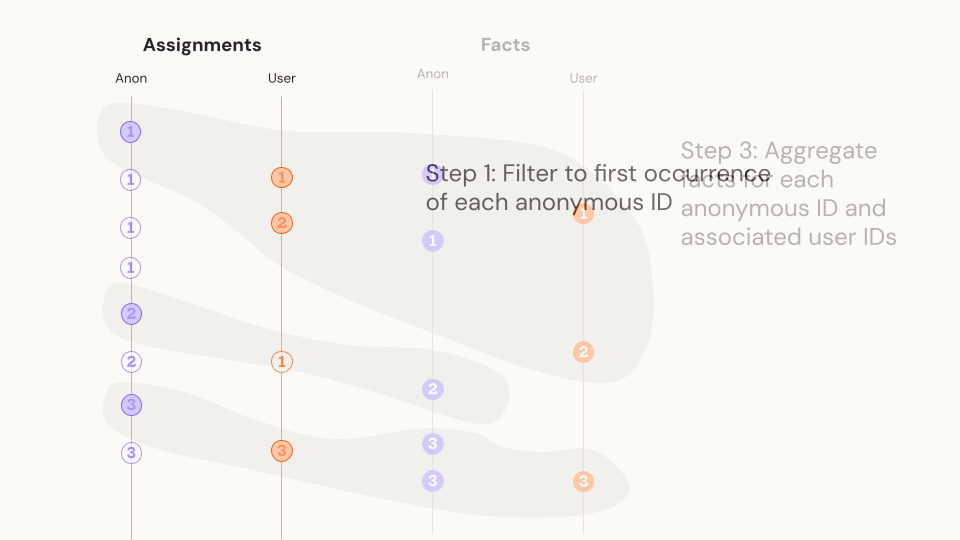
- Filter to each Anonymous ID's first record during the experiment. If the Anonymous ID was associated with more than one variant, remove it from downstream analysis
- For each Anonymous ID, determine the unique set of User IDs that was associated with it*
- Join to both Anonymous ID and User ID metrics using the appropriate join column, aggregate metric events by Anonymous ID
*In step 3 we need to make sure each User ID is associated with only one Anonymous ID to avoid double counting post-authentication events (e.g., purchases). To ensure this, we associate each User ID with its first Anonymous ID during the course of the experiment.
Assignment SQL set up in Eppo
By default, secondary IDs are disabled in Eppo workspaces. To have secondary IDs enabled in your workspace, please contact support@geteppo.com. Also note that funnel metrics and metrics that use the Count Distinct aggregation are not supported in experiments with secondary IDs.
Before setting up an anonymous user assignment SQL, make sure you have created entities for both anonymous users and logged in users, along with one or more metrics.
To add a secondary Entity ID to an assignment source, write a query to return both the primary ID (e.g., anonymous_id) and the secondary ID (e.g., user_id), along with the other typical assignment SQL columns. Then, on the right side panel, add the secondary entity column(s) to the table annotation:
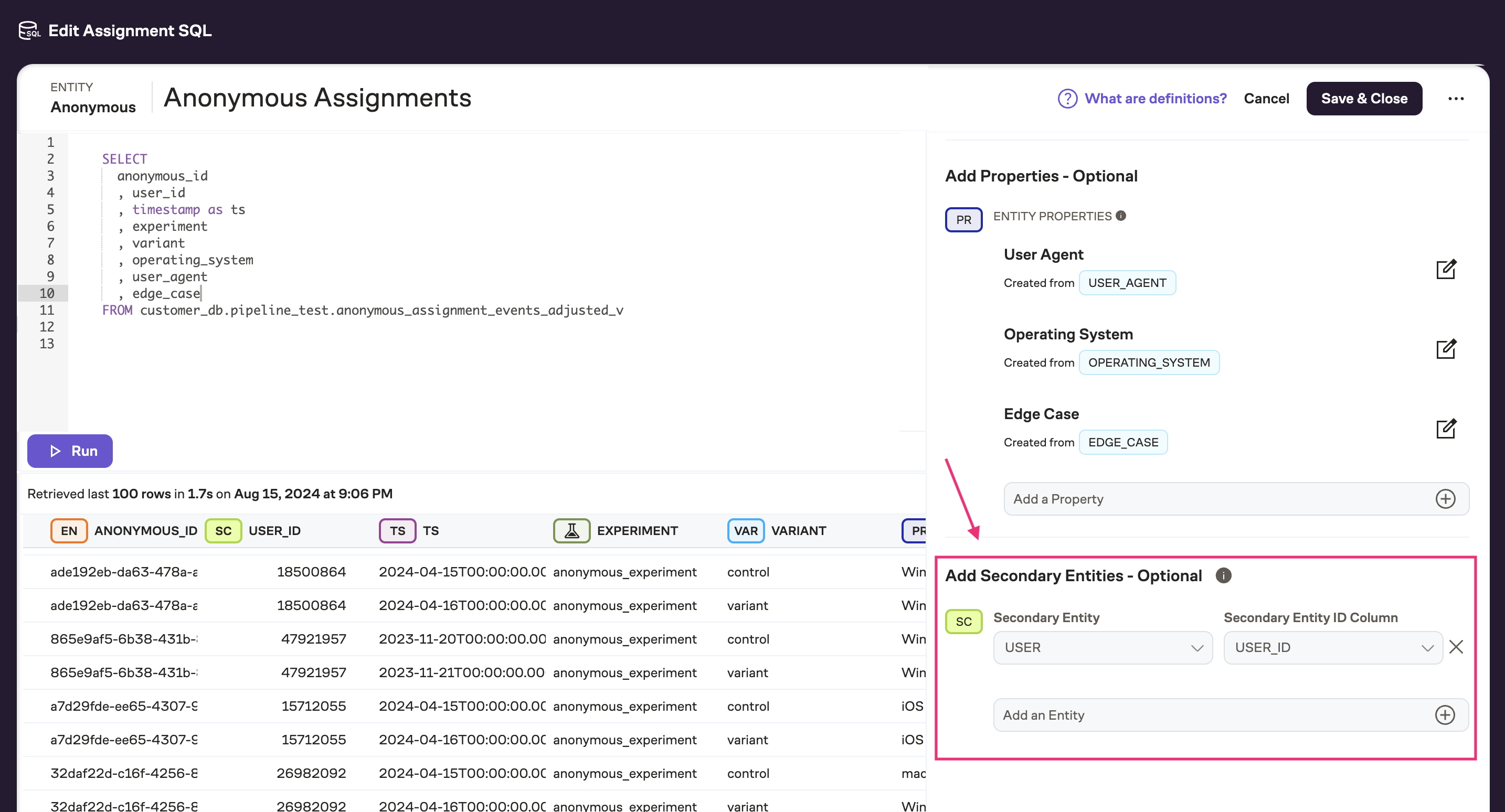
Now, when you go to create an experiment analysis and select Anonymous User as the entity, you'll see an option to specify the analysis method. Under "secondary entity", select User:
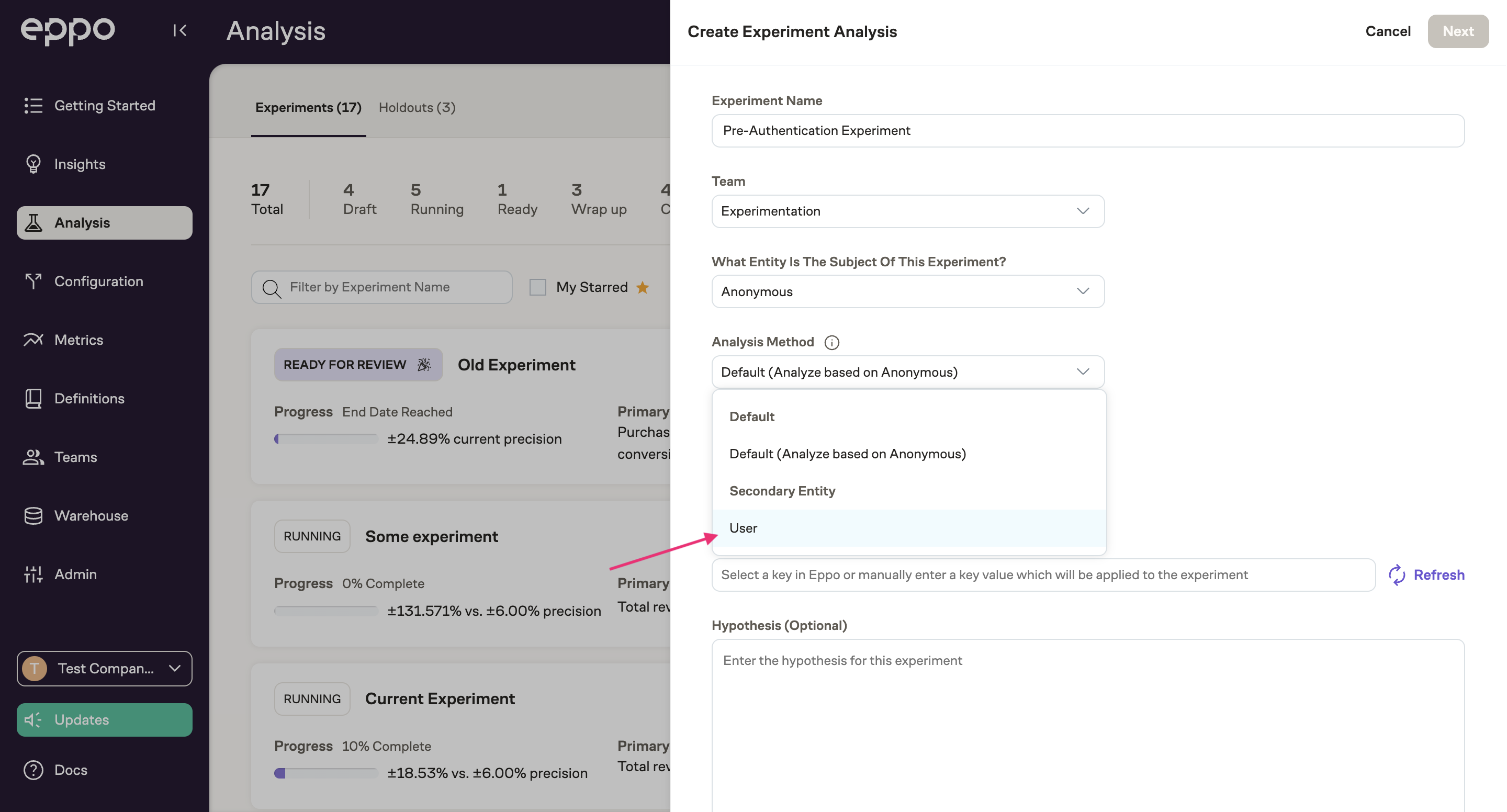
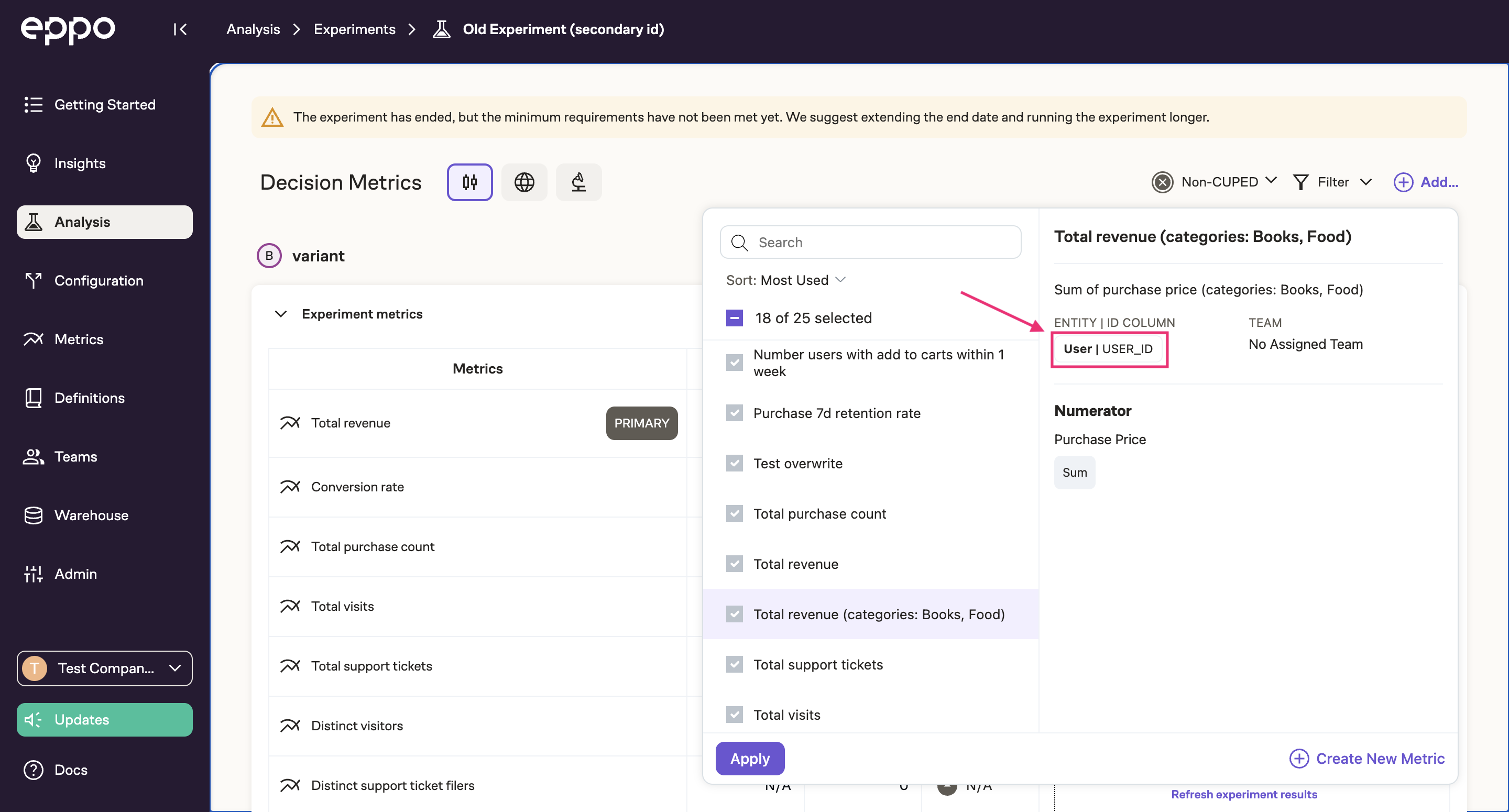
Once you've finished configuring the experiment, you'll be able to add metrics associated with either the Anonymous entity or the User entity!
Data modeling considerations
The approach above assumes you have relatively dense assignment data. That is, if an anonymous ID is later associated with a user, there will be a corresponding event in the assignment logs. This can be error prone. If a user is assigned on the initial landing page and then converts on a different page, it's easy to imagine the assignment log not having a record with that association. To solve this, we can simply do a one time join between the raw assignment table and another table with the full set of timestamped associations:
WITH timeboxed_associations as (
SELECT
user_id
, anonymous_id
, ts
, lag(ts) OVER (PARTITION BY anonymous_id ORDER BY ts) as last_anon_association
, lead(ts) OVER (PARTITION BY anonymous_id ORDER BY ts) as next_anon_association
FROM user_anonymous_associations
)
SELECT
a.anonymous_id
, nvl(a.user_id, ta.user_id) as user_id
, a.experiment
, a.variant
, a.ts
FROM assignments a
LEFT JOIN timeboxed_associations ta
ON a.anonymous_id = ta.anonymous_id
AND (ta.last_anon_association is null or a.ts > ta.ts)
AND (ta.next_anon_association is null or a.ts <= ta.next_anon_association)
By adding this to your assignment data model you can be sure to capture every association between anonymous IDs and users.
Statistical considerations
The approach outlined above treats each anonymous ID as a unique subject in the experiment. The astute reader may be concerned about this violating assumptions around independent and identically distributed (i.i.d.) metrics. Specifically, we expect the relationship between two Anonymous IDs associated with the same User ID to be correlated. It might be tempting to instead aggregate by User ID. This would however present two new issues. First, users may experience both variants. It's straightforward to filter these user's out in the Eppo analysis, but this preferentially removes more active users (a users with three associated Anonymous IDs is more engaged than a user with one) and can lead to biased experiment results.
Second, it's undeniable that most users who have multiple anonymous IDs will never log in on every device. That is, there will inevitably be some Anonymous IDs that are indeed correlated but their relationship is never observed in event logs. Removing only records where this relationship is observed seems arbitrary and again leads to under sampling more engaged users.
Ultimately the decision to treat Anonymous IDs as the subject in experiments comes with a tradeoff. It may in some cases slightly violate the i.i.d. assumption, but it does avoid complications that arise from the alternative user-based approach. That said, some teams may opt to do attribute a different way. One very practical reason is that other teams may already rely on a specific attribution model. Fortunately, since Eppo is warehouse native it's easy to continue to use your existing attribution logic. This is discussed further in the next section.
Using your own existing attribution
Since Eppo uses the data in your warehouse it's very easy to leverage existing attribution models that connect Anonymous IDs and User IDs. Many companies built their own attribute logic to combine both IDs into a single "combined ID". This ID can then be added to both pre-authentication (Anonymous ID) tables and post-authentication (User ID) tables. By creating a single "Combined ID" entity, you can then tell Eppo to simply use this column to join assignments to facts.
This gives you two options: either continue to use your existing attribution and point Eppo at tables with resolved IDs, or point Eppo at your raw data and have Eppo handle the attribution.